
Explore secure data warehousing using the VGS Vault Tokenizer Native App on Snowflake. We walk you through the process of tokenizing sensitive data, managing user roles, configuring data tiers, and integrating tokenization into your data pipeline on Snowflake for improved security and compliance.
What is Tokenization?
Tokenization is the process of protecting sensitive data by creating a “token” that represents the data while storing the original securely in a third-party “vault.” For example, rather than storing social security numbers in their original format, the values can be stored in the VGS vault, and all you need to store is the VGS token that represents the data.

In today’s world, data privacy and storage regulations have become increasingly more strict, and data leaks have become more costly. Tokenization is the way for security and data teams to stay compliant and secure with no impact on data integrity.
Tokenization vs De-identification: What’s the Difference?
De-identification is the process of cleaning production data prior to use during the software development lifecycle. The main purpose of de-identification is to ensure developers have realistic data when writing code and recreating production problems in their local environment.
The differentiating characteristic is that tokenization is reversible given the proper access permissions while de-identification is non-reversible. This makes de-identified data useless in a production environment.
Tokenization is the process of obscuring high-risk data while still supporting the option to see the original data in the future. The ability to store data in a secure vault and selectively reveal the original value to privileged users is key to implementing easily maintainable controls for augmenting, enriching, and sharing data sets
Tokenization != Encryption
Encryption is the process of transforming sensitive data into a coded form using cryptographic algorithms, rendering it unreadable to unauthorized individuals without the corresponding decryption key.
Encryption is useful for storing data securely but introduces problems when providing the data to line-of-business users who need to join tables using sensitive data columns or create human-readable reports. Tokenization on the other hand allows the data admin to reliably create the same token for a given value throughout the entire data warehouse. This allows tables to be joined using sensitive data columns the same way they would be in their un-tokenized form. The data admin can also specify the “alias format” that they wish to use, which means they can preserve elements of the original data, maintaining the usefulness of the data to the line of business.
Below is an example of how a social security number might look after being tokenized.
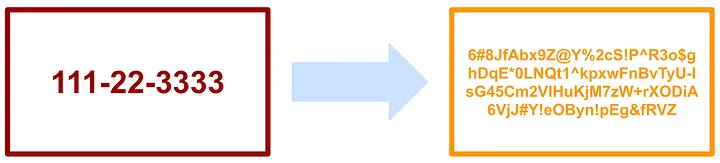
Another point of concern when encrypting data for storage is the management of the decryption key. When data is encrypted, it is always going to be possible to decrypt the encrypted value with the corresponding decryption key. This makes the key rotation process very cumbersome because it requires that the data be fully decrypted with the original key and then re-encrypted with a new encryption key. Tokenization on the other hand allows access keys to be rotated on whatever frequency is specified by an agency’s security team without any additional operations being required on the previously-tokenized data.
Tokenization is More Than Data Masking
Data masking is the process of replacing data with fictional or modified information that maintains the original structure of the data. Although masked data is typically reversible, the approach differs from tokenization because the original value is not stored in a third-party vault, making it difficult to implement controls on which users are allowed to see the sensitive information and which users can only see the tokenized versions.
Introducing VGS
VGS is the world’s largest cloud-based tokenization provider. With the VGS tool suite, enterprises protect their users and systems from seeing any sensitive data, whether it be Personally Identifiable Information (PII) or Payment Card Industry (PCI Data). After data is tokenized in the VGS vault, only users or processes who are explicitly provided permissions can reveal the original data.
The VGS Vault Tokenizer is the only native app on Snowflake focused on tokenizing sensitive data and controlling which roles have access to the original versions. It is the easiest way for data and security teams to achieve compliance and security while retaining the usability of the data for their line-of-business users.
A Tale of Tokenization: Enabling Business Users while Maintaining Fine-Tuned Controls
The VGS Vault Tokenizer Snowflake app allows data stored in a Snowflake table to be tokenized. The process is made simple for the user by configuring the app in the Snowsights UI.
Take, for example, the Acme Bank. The leaders of the data department at this bank are responsible for securely managing millions of records of customer data in their Snowflake data warehouse. Many of these records contain high-risk PII, such as social security numbers, driver’s license numbers, tax ids, and more.
Prior to the VGS Vault Tokenizer app, managing the security and the tokenization of high-risk data was a cumbersome and dangerous process. It meant that either the analysts querying the data were exposed to higher-risk data than they needed, or the Snowflake administrators were required to remove access to the data altogether.
The additional controls required to remove access to this data caused the data team headaches during the data onboarding phase. It also meant that the analysts were unable to join internal data sets to study and use the data effectively, which led to delayed insights for the broader Acme Bank team.
After installing the VGS Vault Tokenizer app in their Snowflake instance, the Acme Bank data team was able to easily configure all of the columns that contained sensitive data. VGS took care of tokenizing each of the existing records in the Snowflake tables, as well as any new data being onboarded into the data warehouse.
Below is a simplified visualization of a VGS Vault Tokenizer app tokenization process of a single Acme Bank’s Snowflake table.
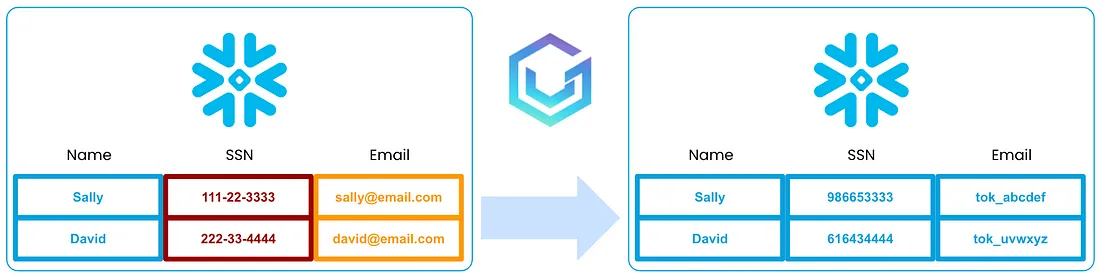
Configuring the VGS Vault Tokenizer
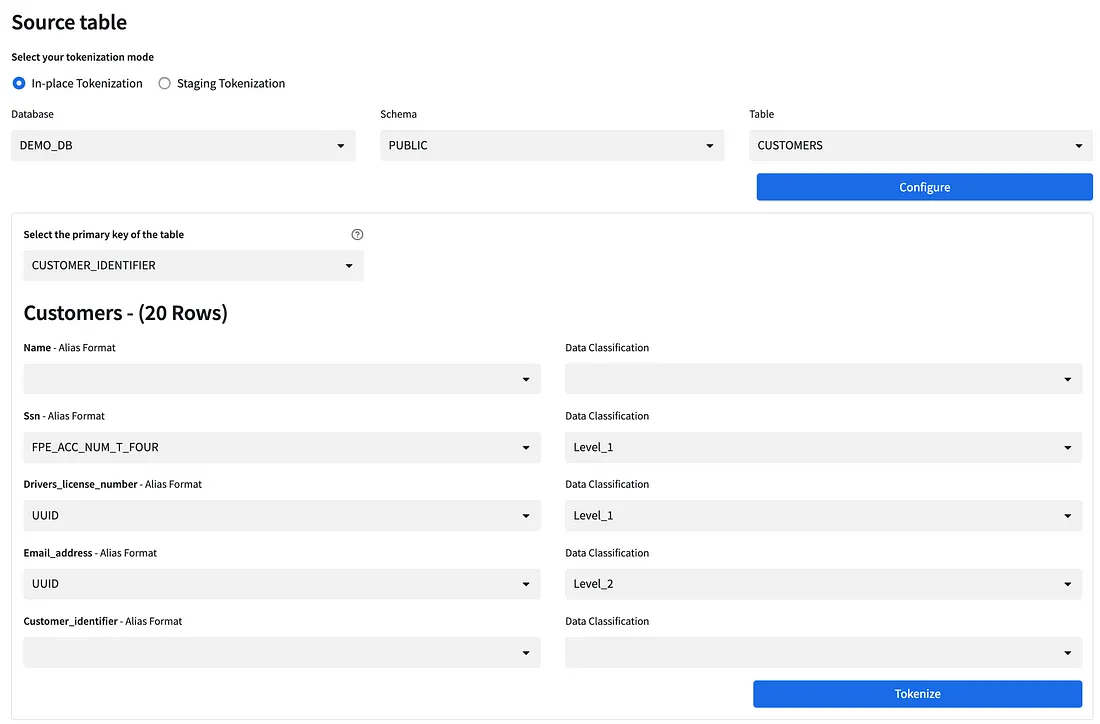
The diagram below shows how the Acme bank team was able to configure which fields required tokenization on one of their tables. On this screen, the user has selected the “CUSTOMERS” table and has chosen to tokenize the “ssn”, “drivers_license_number”, and “email_address” columns.
Enabling Privileged Users with Data Tiers
When deciding how to protect data, users should be granted the appropriate privileges to access un-tokenized data.
The VGS Vault Tokenizer app allows administrators to set up any number of data tiers that makes sense for their organization. These data tiers are then granted to users using the user roles that are built into Snowflake.
In Acme Bank’s case, they opted to set up three data tiers in the VGS Vault Tokenizer app:
- Level 3: This tier represents any non-sensitive data in the data lake. This may include first names or tokenized values. When Acme Bank analysts who only have access to Level 3 data query tables, any sensitive data is presented to them in a tokenized format.
- Level 2: This tier applies to any customer contact information. This may be a customer’s email, phone number, or shipping address. However, users who can access Level 2 do NOT have access to government-issued id numbers. In this example, Acme Bank chose to grant this level of access to the “Senior Analyst” role in Snowflake.
- Level 1: This tier is for any high-risk data in the system. Users who are granted access to Level 1 data are trusted to see the original un-tokenized values for all customer information, including government-issued IDs. At Acme Bank, this level of access is only granted to the “Data Owners” role in Snowflake.
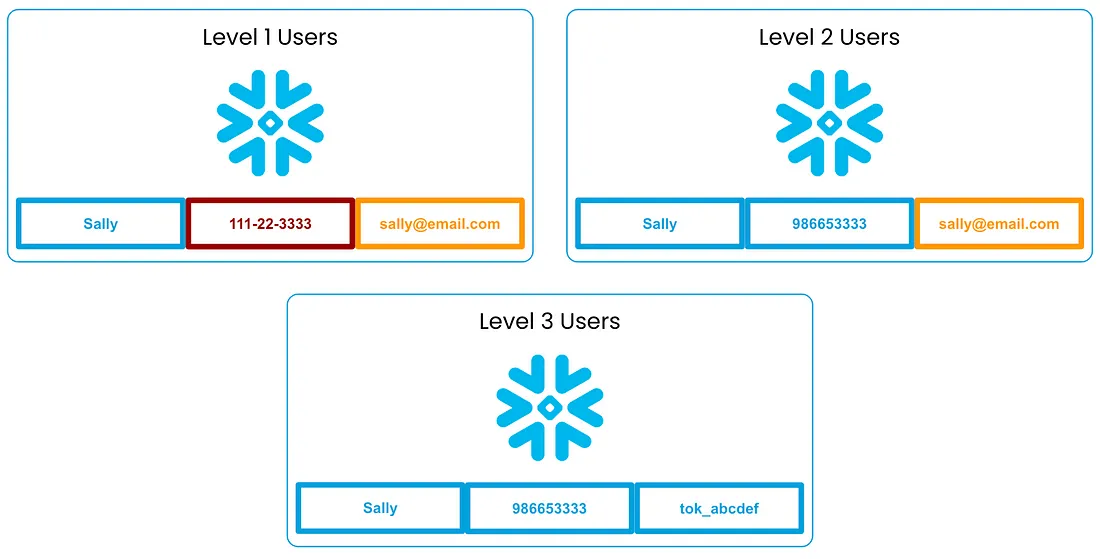
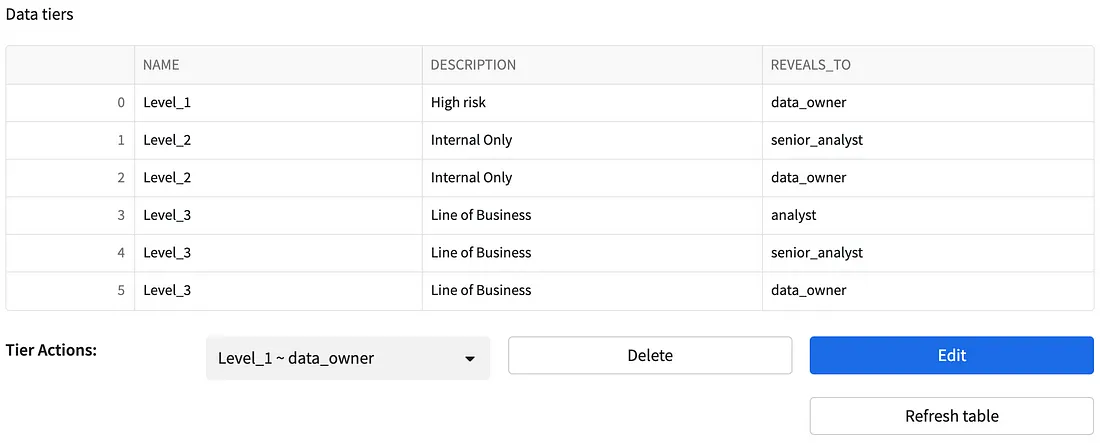
Configuring Data Tiers
The diagram below shows how Acme Bank’s data tiers are configured. Notice the “data_owner” is the only role with access to the “High risk” Level_1 Data tier.
Alias Formats
When tokenizing data, there may be the need to preserve different elements of the original value.
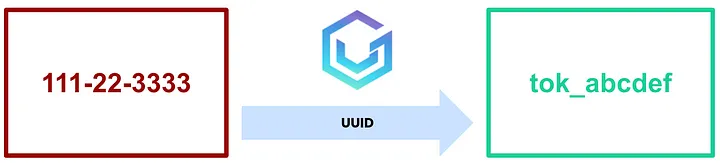
Below is a visualization of how an SSN would be tokenized with the “UUID” alias format. Note that the tokenized value has no obvious relation to the original value.
In Acme Bank’s situation, the data team decided that it was important for analyst users (Level 3) to be able to see the last 4 digits of the original SSN. This was implemented by selecting the FPE_ACC_NUM_T_FOUR alias format for that column in the VGS Vault Tokenizer app. The tokens created with this format will preserve the last 4 digits of the account number while keeping the token numeric.

Utilizing Tokenized Columns
VGS gives a one-to-one relationship between the original data and the tokenized data, meaning users can join tables on tokenized columns just as easily as they would before tokenization occurred.
Below is a visualization of a Customer and Accounts table in Acme Bank’s Snowflake environment. In this situation, the only shared column value is the SSN. VGS has sanitized the values in both tables with the same tokens allowing the tokenized data to be used to join the tables.
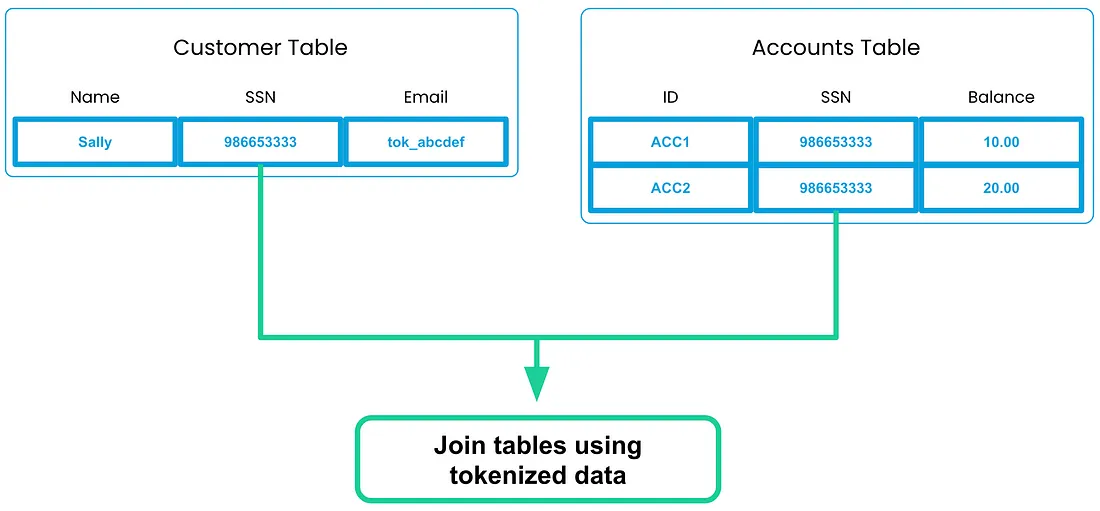
Using the simple query below, Acme Bank analysts were able to pull the sum of all of a customer’s accounts. By joining the two tables using the tokenized column, the analysts at Acme Bank are able to get insights into customer data without being exposed to any high-risk data elements.
‘’‘SELECT c.name, c.ssn, SUM(acc.account_value)
FROM customers c
JOIN accounts acc ON c.ssn = acc.account_ssn
GROUP BY c.name, c.ssn;’‘’
Adding Tokenization to a Data Pipeline
In the previous examples, Acme Bank was concerned about tokenizing data that was already in their Snowflake environment. But what about new data coming in from their vendors and partners?
The solution: Staging Tokenization.
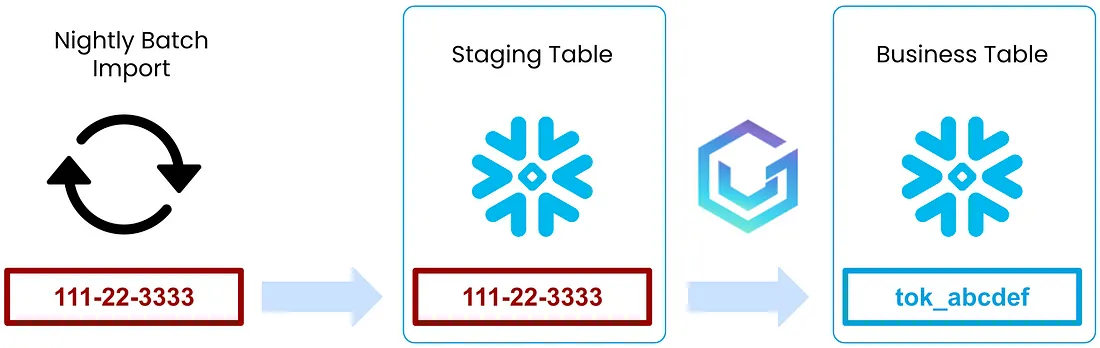
The VGS Vault Tokenizer app can be configured to allow data to be securely imported into a staging table. The data will then be picked up by the VGS Vault Tokenizer, tokenized, and moved into a target table where it can be used by the users who query the data for business information.
Using staging tables, Acme Bank was able to import millions of data records into their Snowflake data warehouse every night without having to worry about high-risk data being exposed to users who do not have permission to see it.
Below is a visualization of Acme Bank’s daily import process.
Configuring Staging Tokenization
The VGS Vault Tokenizer app allows you to easily define the Source and Target tables for this staging process. The Source table is the table where the data is going to be staged. The Target table is the table your business users will use to query the data.
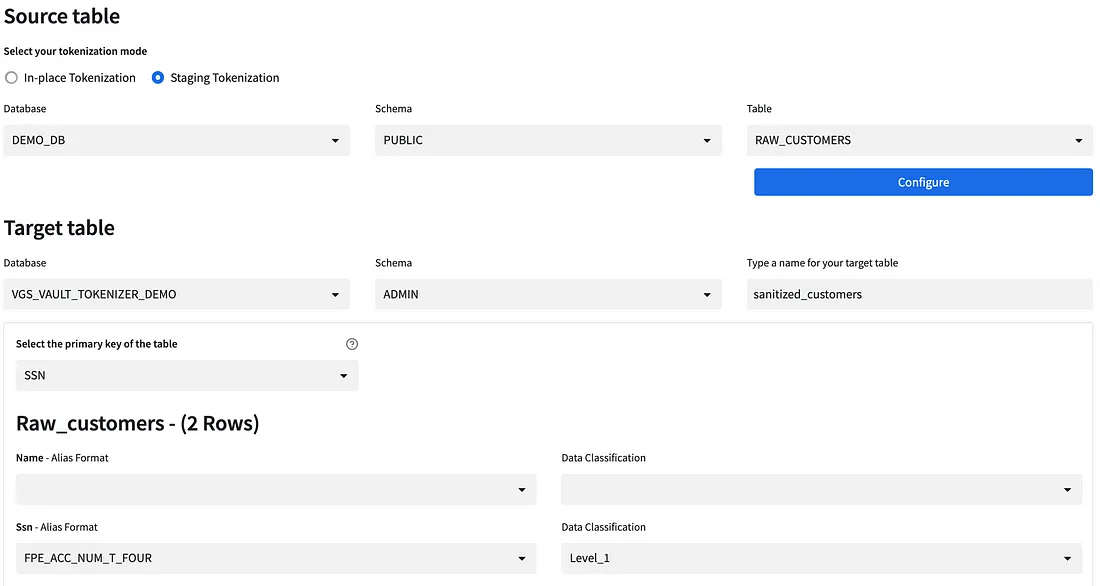
Note that staging tables should only be accessible by admins of the VGS Vault Tokenizer app.
How do you get started?
For detailed instructions on setting up the VGS Vault Tokenizer Snowflake app follow this link. If you have any questions, reach out to VGS at support@verygoodsecurity.com!



